


인덱스는 신이고 나는 무적이야
부동산 프로젝트를 진행하다가 지도 중심을 기준으로 N km 이내의 아파트와 주변 시설들을 반환하는 api를 만들어야 했다. MySQL 공간 함수 중에 ST_DISTANCE_SPHERE 라는 친구가 있길래 요놈을 가져다가 만들었는데 웬걸.. 반환까지 평균 3초가 걸렸다. 메인 기능이 성능이 이럼 안 되겠다 싶어, 인덱스 적용을 고민하고 진행했다. 이번엔 공간 데이터와 공간 인덱스를 알아보자.



MySql공간 데이터
먼저, 공간 데이터를 알아보자
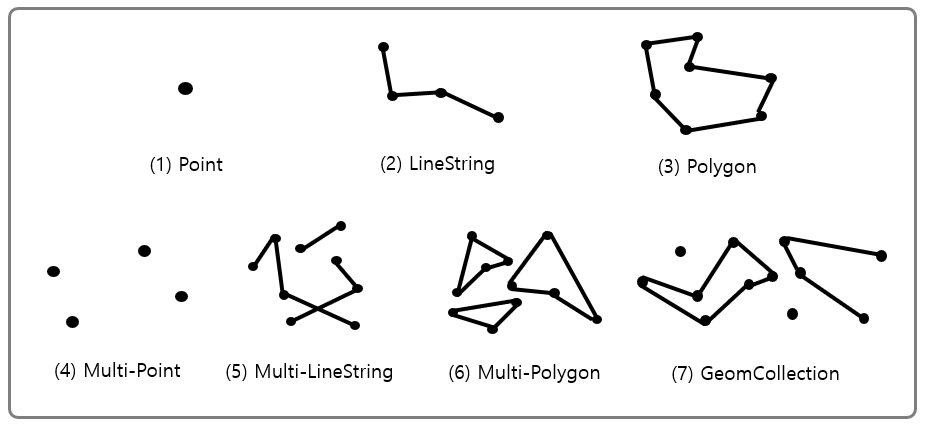
| Point | 좌표 공간의 한 지점 | POINT(10 10) |
|---|---|---|
| LineString | 다수의 Point를 연결해주는 선분 | LINESTRING(10 10, 20 20, 30 30) |
| Polygon | 다수의 선분들이 연결되어 닫혀있는 상태 | POLYGON((10 10, 10 20, 20 10, 10 10)) |
| Multi-Point | 다수의 Point 집합 | MULTIPOINT(10 10, 20 20) |
| Multi-LineString | 다수의 LineString 집합 | MULTILINESTRING((10 10, 20 20), (15 15, 25 25)) |
| Multi-Polygon | 다수의 Polygon 집합 | MULTIPOLYGON(((10 10, 10 20, 20 10, 10 10)), ((40 40, 30 30, 40 40))) |
| GeomCollection | 모든 공간 데이터들의 집합 | GEOMETRYCOLLECTION(POINT(10 10), LINESTRING(20 20, 30 30)) |
MySql에서는 지리 정보와 같은 공간 데이터를 관리할 수 있도록 총 7가지 형태의 타입을 제공하고 있다. 이를 이용해서 위도, 경도와 같은 데이터를 문자열이 아닌 공간 데이터로써 적절하게 사용 가능하다.

lng, lat는 varchar 타입의 문자열로 저장한 예시이고 local_point는 Point 타입으로 (경도, 위도) 형태로 저장되어 있다.
SELECT
apartment_name,
lng,
lat,
local_point
FROM houseinfo
WHERE st_x(local_point) = 126.153432906048
AND st_y(local_point) = 36.6893909820548
카밀리아하우스를 조회하기 위해서 Point 타입을 조건으로 주고 조회했을 때 정상적으로 반환되는 것을 확인할 수 있다.
공간 인덱스
공간 인덱스는 지리적 정보를 효율적으로 검색하기 위해, 공간 데이터에 적용시키는 인덱스로 최소 경계 사각형 이용한 R-Tree 자료 구조로 관리된다.
create table tmp(
id int auto_increment primary key,
local_point POINT not null srid 4326,
spatial index (local_point)
);공간 데이터를 다룰 땐 SRID를 신경 써야 한다. 지구 표면 위의 위치를 정의하는 좌표계를 나타내며 SRID 값에 따라 위치 정보가 바뀔 수 있다. 가장 일반적으로 사용하는 값은 WGS 84(4326)이다. 프로젝트의 상황에 맞게 적절한 값을 사용하도록 하자.

MBR 최소 경계 사각형
MySql의 공간 인덱스는 일반적인 인덱스와는 다르게 R-Tree 자료 구조를 사용한다. 이를 이해하기 위해선 먼저 최소 경계 사각형에 대해서 알아보자.

공간 데이터 타입에는 크게 Point, LineString, Polygon이 있다. 최소 경계 사각형은 해당 도형들을 감싸는 사각형을 이야기한다. 위의 이미지에서 최소 경계 사각형을 그리게 되었을 때를 살펴보자.
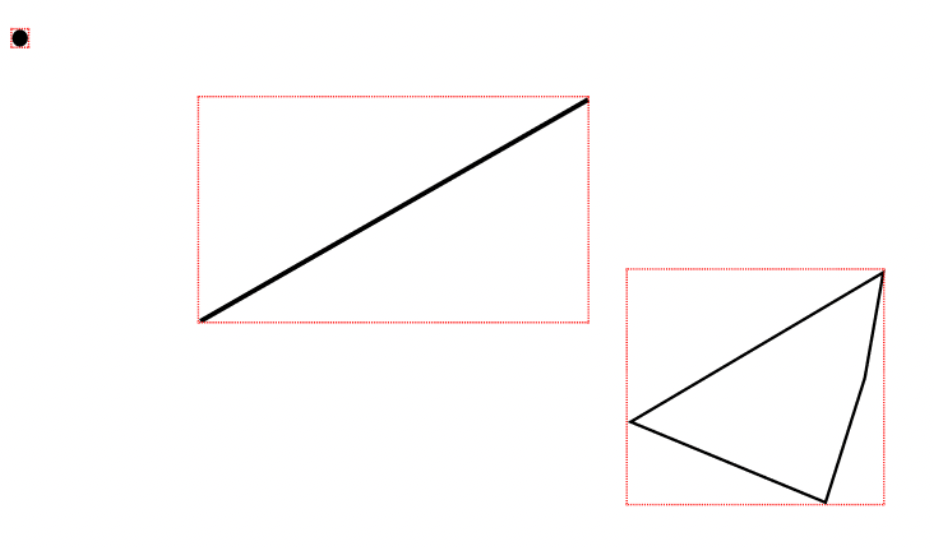
위의 그림에서 보이는 빨간 사각형이 MBR. 즉, 최소 경계 사각형이다. R-Tree는 MBR을 그리고 MBR 들의 최소 경계 사각형을 또 그리고.. 또.. 또.. 작업을 반복하여 하나의 트리 구조를 형성하게 된다. 아래 지도를 통해 다시 이해해 보자.

지도에 Point(주황) LineString(파랑) Polygon(초록) 공간 데이터가 있다고 가정해 봤을 때 도형들의 최소 경계 사각형은 아래와 같다.

각 도형들을 MBR로 묶었으며 MBR끼리 계속해서 묶다보면

해당 그림처럼 MBR들을 모두 묶어 하나의 트리 구조를 형성하여 R-Tree를 만들 수 있다. 공간 인덱스는 이렇게 만들어진 R-Tree를 이용하여 지리적 정보를 효율적으로 검색한다. 그럼 이제 공간 인덱스를 사용해 보자.
공간 인덱스가 사용되지 않는 경우
SELECT *
FROM houseinfo
WHERE ST_Distance_Sphere(
local_point,
ST_GeomFromText('POINT(126.153432906048 36.6893909820548)', 0)
) <= 1000;카밀리아하우스를 기준으로 반경 1km 이내의 부동산 정보와 주변 시설을 검색하는 쿼리다. 필자는 임시로 SRID를 0으로 지정했기 때문에 ST_GeomFromText의 2번째 매개변수가 0이다 SRID의 값이 4326이라면 0 대신 4326을 넣도록 하자.
그럼 해당 쿼리는 인덱스를 사용하는지 쿼리 실행 계획을 살펴보도록 하자. MySql의 쿼리 실행 계획을 확인하기 위해선 쿼리 맨 앞에 explain을 붙여주면 된다.

쿼리 실행 계획에 대한 자세한 내용은 다음에 다루도록 하고 일부 항목만 살펴보도록 하겠다.
table- 접근 테이블
type- 어떤 접근 방식이 효율적인지를 나타냄
- 어떤 인덱스가 사용되고 이를 통해 어떻게 쿼리를 튜닝해야 하는지 방향성을 잡을 수 있음
possible_key- 데이터를 검색하는 데 사용이 가능한 키로 인덱스 정보도 포함됨
key- 실제로 데이터를 검색하는 데 사용되는 키
extra- 옵티마이저가 동작하는 걸 하려 주는 힌트
현재 실행 계획을 보면 Type이 ALL이며 사용 가능한 키, 실제 사용하는 키가 null이다. 인덱스를 설정했음에도 불구하고 사용하지 않고 있다는 것을 알 수 있다. 여러 가지 이유가 있겠지만 해당 쿼리가 인덱스를 사용하지 않는 이유는 ST_Distance_Sphere는 테이블을 풀스캔 하는 공간 함수다. 즉, 인덱스가 유무와 상관없이 무조건 풀스캔으로 모든 데이터와 기준점을 비교하는 함수이다.

MySql 공식 문서의 일부를 가져왔다. 거리를 계산하는 함수인 ST_Distance_Sphere는 인덱스를 무시하고 데이터 풀스캔을 진행한다.
공간 인덱스가 사용되도록 쿼리 튜닝
그럼 R-Tree를 이용할 수 있는 함수들을 조합하여 쿼리 튜닝을 진행해 보자. 공간 함수 중 ST_BUFFER와 ST_CONTAINS를 사용하도록 하겠다.
ST_BUFFER- 기준 좌표 주변의 반경 N km의 원을 생성
ST_CONTAINS- 두 개의 공간 데이터의 포함 여부를 확인
- 1번 인자에 2번 인자가 있는지 확인
select *
from houseinfo
where
st_contains(st_buffer(ST_GeomFromText('POINT(126.153432906048 36.6893909820548)', 0),0.01), local_point);수정한 쿼리를 확인해 보자
1. ST_BUFFER에 기준점(카밀리아하우스)을 설정하고 기준점에서 약 1km 반경의 원을 그린다.
2. ST_CONTAINS의 1번 인자로 1km 원을 넣고, 2번 인자로 local_point를 넣었다.
즉, 1km 원 안에 포함된 공간 데이터를 반환한다.
그럼 핵심인 인덱스를 제대로 활용하는가?

아까의 실행 계획과 비교했을 때 type은 range, possilbe_key와 key에 인덱스 이름이 나오는 것을 확인할 수 있다.
select h.apt_code, h.apartmentName, h.lng, h.lat
from HouseInfo h
where st_contains(st_buffer(Point(:lng, :lat), :dist), h.localPoint);@Query(value = "select " +
"h.apt_code, " +
"h.apartment_name, " +
"h.lng, " +
"h.lat, " +
"h.build_year," +
"h.avg " +
"from houseinfo h " +
"where st_contains(st_buffer(Point(:lng, :lat), :dist), h.local_point)"
, nativeQuery = true)
List<Object[]> findByApt(@Param("lng") String lng, @Param("lat") String lat, @Param("dist") double dist);
...
@Query(value = "select h.id, h.name, h.phone_number, h.lng,h.lat, cast(round(ST_Distance_Sphere(Point(:lng, :lat), h.local_point), 0) as signed) as dist " +
"from hospital h " +
"where st_contains(st_buffer(Point(:lng, :lat), :dist), h.local_point) " +
"order by ST_Distance_Sphere(Point(:lng, :lat), h.local_point);",nativeQuery = true)
List<Object[]> findByHospital(@Param("lng") String lng, @Param("lat") String lat, @Param("dist") double dist);당시 실제로 사용했던 코드 중 일부다. hibernate 5부터는 geometry를 지원하기 때문에 의존성을 주입하고 JPQL과 QueryDsl을 사용하여 쿼리를 구성할 수 있었으나, 당시에는 QueryDsl 존재자체를 몰랐고 JPQL의 이해도가 부족하여 nativeQuery를 사용했다. 지금 보니 반환값도 Object 배열로 받았으니 추가적인 매핑 코드가 필요했었다.
참고 자료
https://dev.mysql.com/doc/refman/8.0/en/spatial-index-optimization.html
https://tecoble.techcourse.co.kr/post/2023-10-04-spatial-data/
IT
github : https://github.com/HanSungHyeon